Environment
module load compilers/gcc-12.3_sl7
Hello World by std::threads
#include <thread>
#include <iostream>
int main()
{
auto f = [](int i){
std::cout << "hello world from thread " << i << std::endl;
};
//Construct a thread which runs the function f
std::thread t0(f,0);
//and then destroy it by joining it
t0.join();
}
Compile with:
g++ std_threads.cpp -lpthread -o std_threads
Measuring time intervals
#include <chrono>
...
auto start = std::chrono::steady_clock::now();
foo();
auto stop = std::chrono::steady_clock::now();
std::chrono::duration<double> dur= stop - start;
std::cout << dur.count() << " seconds" << std::endl;
Exercise 1. Reduction
#include <iostream>
#include <random>
#include <utility>
#include <vector>
#include <chrono>
int main(){
const unsigned int numElements= 100000000;
std::vector<int> input;
input.reserve(numElements);
std::random_device rd; // a seed source for the random number engine
std::mt19937 engine(rd()); // mersenne_twister_engine seeded with rd()
std::uniform_int_distribution<> uniformDist(-5,5);
for ( unsigned int i=0 ; i< numElements ; ++i) input.emplace_back(uniformDist(engine));
long long int sum= 0;
auto f= [&](unsigned long long firstIndex, unsigned long long lastIndex){
for (auto it= firstIndex; it < lastIndex; ++it){
sum+= input[it];
}
};
auto start = std::chrono::steady_clock::now();
f(0,numElements);
std::chrono::duration<double> dur= std::chrono::steady_clock::now() - start;
std::cout << "Time spent in reduction: " << dur.count() << " seconds" << std::endl;
std::cout << "Sum result: " << sum << std::endl;
return 0;
}
Quickly create std::threads
unsigned int n = std::thread::hardware_concurrency();
std::vector<std::thread> v;
for (int i = 0; i < n; ++i) {
v.emplace_back(f,i);
}
for (auto& t : v) {
t.join();
}
Exercise 2. Numerical Integration
#include <iostream>
#include <iomanip>
#include <chrono>
int main()
{
auto sum = 0.;
unsigned int num_steps = 1 << 22;
auto pi = 0.0;
double step = 1./(double) num_steps;
auto start = std::chrono::steady_clock::now();
for (int i=0; i<num_steps; i++){
auto x = (i+0.5)*step;
sum = sum + 4./(1.+x*x);
}
auto stop = std::chrono::steady_clock::now();
std::chrono::duration<double> dur= stop - start;
std::cout << dur.count() << " seconds" << std::endl;
pi = step * sum;
std::cout << "result: " << std::setprecision (15) << pi << std::endl;
}
Exercise 3. pi with Montecarlo
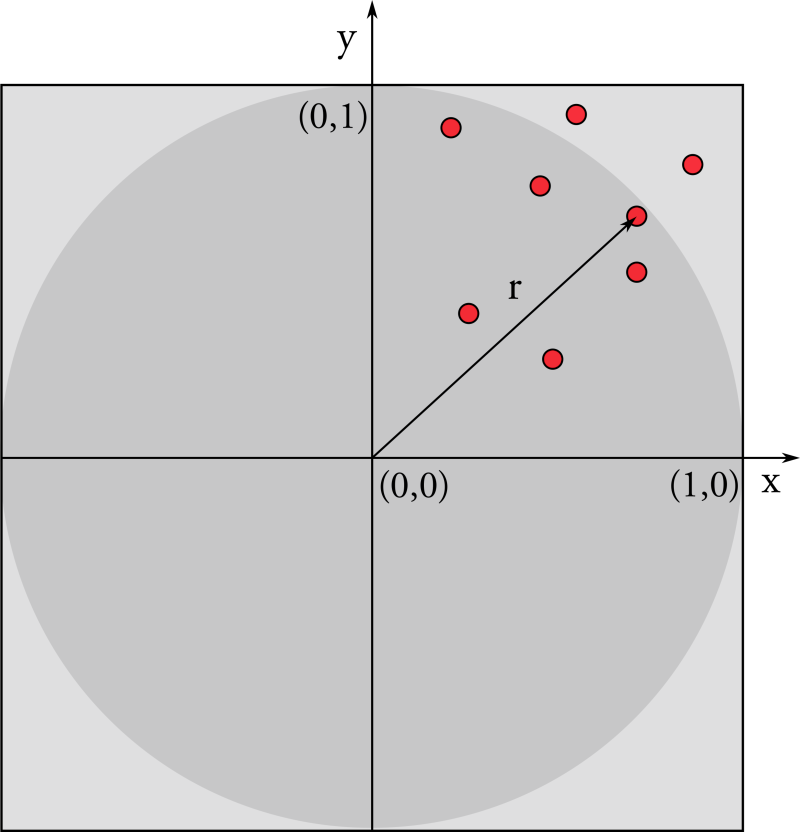 .
.
The area of the circle is pi and the area of the square is 4.
Generate N random floats x and y between -1 and 1 https://en.cppreference.com/w/cpp/numeric/random/uniform_real_distribution.
Calculate the distance r of your point from the origin.
If r < 1: the point is inside the circle and increase Nin.
The ratio between Nin and N converges to the ratio between the areas.
Setting the environment for Intel oneTBB
Download and extract the latest release for Intel oneTBB:
wget https://github.com/oneapi-src/oneTBB/releases/download/v2021.10.0/oneapi-tbb-2021.10.0-lin.tgz
tar -xzf oneapi-tbb-2021.10.0-lin.tgz
Let’s now set the environment to use this version of oneTBB.
module load compilers/gcc-12.3_sl7
source oneapi-tbb-2021.10.0/env/vars.sh intel64 linux auto_tbbroot
echo $TBBROOT
To compile and link:
g++ yourprogram.cpp -ltbb -std=c++20 -o yourprogram
Let’s check that you can compile a simple tbb program:
#include <cassert>
#include <cstdint>
#include <iostream>
#include <oneapi/tbb.h>
#include <oneapi/tbb/info.h>
#include <oneapi/tbb/parallel_for.h>
#include <oneapi/tbb/task_arena.h>
int main() {
// Get the default number of threads
int num_threads = oneapi::tbb::info::default_concurrency();
int N = 10;
std::cout << "Use indices: " << std::endl;
// Run the default parallelism
oneapi::tbb::parallel_for(0, N, [=](int i) {
std::cout << "Hello World from element " << i << std::endl;
std::cout << "number of threads: "
<< oneapi::tbb::this_task_arena::max_concurrency() << std::endl;
});
// Run the default parallelism
std::cout << "\n\n\nNow use oneapi::tbb::blocked_range" << std::endl;
oneapi::tbb::parallel_for(
oneapi::tbb::blocked_range<size_t>(0, N), [=](auto &r) {
for (auto i = r.begin(); i < r.end(); ++i) {
std::cout << "i= " << i << std::endl;
}
std::cout << "number of threads: "
<< oneapi::tbb::this_task_arena::max_concurrency()
<< std::endl;
});
// Create the task_arena with 3 threads
std::cout << "\n\n\nNow use a task_arena with 3 threads" << std::endl;
oneapi::tbb::task_arena arena(3);
arena.execute([=] {
oneapi::tbb::parallel_for(
oneapi::tbb::blocked_range<size_t>(0, N),
[=](const oneapi::tbb::blocked_range<size_t> &r) {
for (auto i = r.begin(); i < r.end(); ++i) {
std::cout << "Hello World from element " << i << std::endl;
}
std::cout << "Number of threads in the task_arena: "
<< oneapi::tbb::this_task_arena::max_concurrency()
<< std::endl;
});
});
}
Compile with:
g++ your_first_tbb_program.cpp -ltbb
Your TBB Thread pool
// analogous to hardware_concurrency, number of hw threads:
int num_threads = oneapi::tbb::info::default_concurrency();
// or if you wish to force a number of threads:
auto t = 10; //running with 10 threads
oneapi::tbb::task_arena arena(t);
// And query an arena for the number of threads used:
auto max = oneapi::tbb::this_task_arena::max_concurrency();
// Limit the number of threads to two for all oneTBB parallel interfaces
oneapi::tbb::global_control global_limit(oneapi::tbb::global_control::max_allowed_parallelism, 2);
Task parallelism
A task is submitted to a task_group as in the following.
The run method is asynchronous. In order to be sure that the task has completed, the wait method has to be launched.
Alternatively, the run_and_wait method can be used.
#include <iostream>
#include <oneapi/tbb.h>
#include <oneapi/tbb/task_group.h>
using namespace oneapi::tbb;
int Fib(int n) {
if (n < 2) {
return n;
} else {
int x, y;
task_group g;
g.run([&] { x = Fib(n - 1); }); // spawn a task
g.run([&] { y = Fib(n - 2); }); // spawn another task
g.wait(); // wait for both tasks to complete
return x + y;
}
}
int main() {
std::cout << Fib(32) << std::endl;
return 0;
}
Solutions
Some possible solutions to the exercises are posted here:
https://github.com/infn-esc/esc23/tree/main/hands-on/stdthreads_tbb